What is SRE and what is the role of SRE teams?
SRE stands for Site Reliability Engineering and originates from Google, where it has spread all over the industry. The set of practices used in SRE are closely related to DevOps (mostly the Ops part), but with a focus on creating scalable and highly reliable software systems to benefit end users.

SRE teams must balance between deploying new features quickly and making those features reliable to consumers. They use software engineering techniques to automate and solve infrastructure and operations problems. One of those problems is maximizing the number of releases one can achieve and determining which features are a fit for the production by using service-level indicators (SLIs) and service-level objectives (SLOs).
SLIs are metrics assessing the performance of specific aspects of a service. They may involve request latency, availability, error rate, and system throughput. An SLO is a defined target or range for a specific aspect of a service's performance that is based on SLIs.
In short, SRE teams are a specialization of DevOps that think about site reliability, scalability, and downtime. They implement software solutions and best practices, including playbooks, to automate operations tasks. Think about how a fully automated continuous delivery with multiple production deployments every day can benefit your organization. This is possible, and it’s been used in companies like Amazon and Netflix for a while now.
What is a playbook?
A playbook is a documented end-to-end guide that, when followed, leads to a desired goal. That goal can be anything from site being brought back up, successful database migration, production deployment on servers, or anything repetitive in the scope of your project that may require some manual input. Ideally, all these processes will be fully automated, but playbooks are one step closer to this utopia.
Playbooks are living documents that change over time to encompass the needs of the team that is using them. They could change after a post-mortem/retrospective — a learning process that takes place after the incident that determines the root cause and actions taken to mitigate/resolve the incident. They can also undergo changes when there is a great need for an update (like when you have changed the infrastructure, updated the software or new requirements are given that impact the playbook). They are usually written by DevOps engineers, SRE team members, or developers who are familiar with the process and understand the benefits of a well-written, well-documented process.
The purpose of the playbook is to help playbook owners, or their colleagues perform routine tasks or crisis management and response when under pressure, or when a process that tolerates no mistakes is not fully automated (e.g., a production deployment of your precious application). Playbooks generally increase the efficiency of the team and its members, help reduce common mistakes, and serve as great knowledge-sharing tools. It should be noted that playbooks, as well as runbooks, are not a replacement for the classical documentation because they all serve different purposes and have their own place in the Software development life cycle.
Runbook vs. playbook - is there a difference?
Playbooks describe steps to remediate larger issues or to complete a major task (e.g., production deployment), and often contain multiple runbooks. On the other hand, runbooks focus on individual tasks that are commonly repeated throughout the development and/or operations lifecycle. Playbooks are more process-oriented, while runbooks tend to be more technical.

In the analogy of a production deployment, a runbook could be used to describe a database migration. Runbooks and playbooks are part of ITIL protocols that provide guidance on best practices for IT service management aimed at aligning IT services with the needs of business. They can be automated to some degree. In this blog, the focus is on playbooks because they’re more versatile and one can find a use for them outside classic development and operations processes.
What are the best practices for writing playbooks?
It turns out that the secret recipe is to simply start writing and using them regularly or wherever there are benefits from them. Sounds simple, but when you have never encountered a playbook before, it can seem scary because you are in unfamiliar territory. That’s ok, because in the coming text are some examples that we at Vega IT found useful for our projects. Of course, every project is unique and requires different tools and knowledge, but the basic ideas for approaching a project are the same (scoping, estimation, deployment, documentation, etc.).
To make a quality playbook you need to understand the process and the end goal of it. Without understanding what you are trying to automate, document, or record, the playbook will lack some crucial details and can miss some critical or edge cases that are unique to your processes, whether it’s the unique steps that make the process, unique infrastructure, or something else entirely.
Playbooks must be regularly reviewed, tested, and updated to be up-to-date and continue to serve their purpose. Every role that’s part of the process described by the playbook, either directly (e.g., developers who will do a deployment) or indirectly (e.g., product owners who will want to know if a product has stopped working), should be aware of the playbooks existence and should be included in creating and maintaining that playbook, at least by giving their thoughts on it.
Start from the process that already exists and you want it to be covered in the playbook. Look at some existing examples online and try to write an easy-to-understand guide, no matter who will use it. This will help you in case that the person responsible for one part of the system goes on a holiday and someone needs to take over. When you gain confidence in writing a playbook, you can raise the bar by describing processes that don’t happen very often (or haven’t happened before), but you consider them an important, even critical, part of the system. The format of the playbook is not too important – it can be a text document, a flowchart, a checkbox list, and so forth. In this article, there will be an example written as a text document and a flowchart that may be valuable to anyone just starting with playbooks.
Sometimes your playbook will need rewriting in the beginning. It may also require some additional updates from time to time as you change the tools, processes, or people involved in the process. Different people have different styles and preferences when it comes to documenting processes and following written procedures, so make sure that your playbook matches the preferences of the people (or roles) using it.
Also, there is no “one ring to rule them all” approach that will make your playbook universal in all situations and cover every edge case possible, while still maintaining usability and readability so don’t bother writing such a playbook. Understanding and accepting that some parts of a process are non-deterministic and having ideas on how to approach those parts when time comes is a good thing, much better than writing a documentation with an ocean of infinite possibilities that no one can decipher nor use. If you have a post-mortem process, use it to improve the existing playbooks that were used or to discuss whether a new playbook should be written to help next time a similar incident happens.
Must-have playbooks - some real-world examples
We can make a recommendation based on the common patterns found in software development. These include infrastructure provisioning, continuous delivery with release and rollback strategies, system monitoring and audit, and incident management and response. Here are a few examples of how it works.
|
As you can see, this is just a simple, step-by-step list that describes the deployment of some fictional application to production. Of course, you’d have more details describing each of these steps and how to perform them in a real playbook.
In the second image you can see the same example as in the text above, just written using BPMN 2.0 notation.
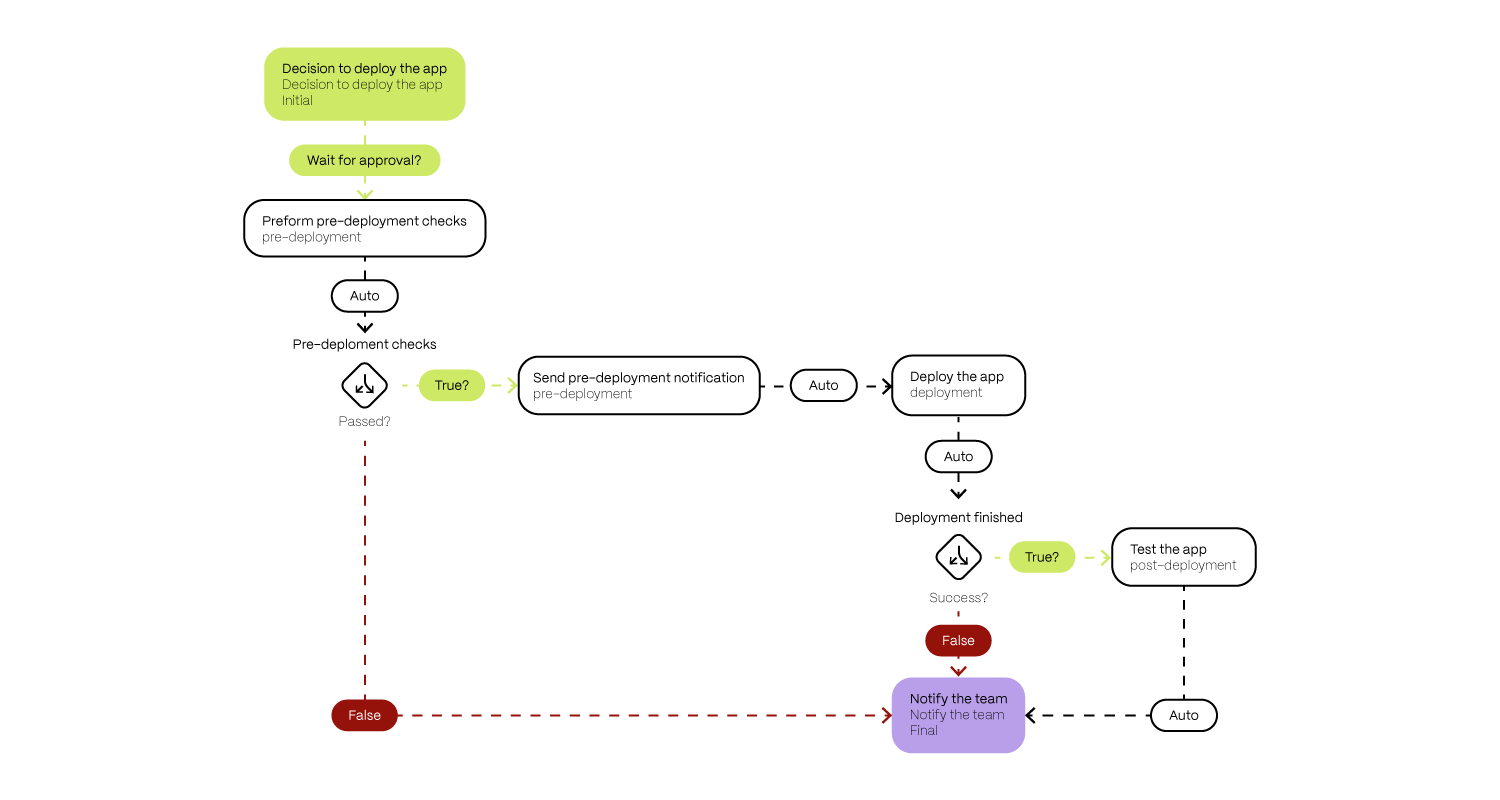
You can choose what is the ideal format for you and use it to create desired playbooks. Perhaps in some situations, a combination of both is the best solution. In the following text are some of our recommendations for common patterns we have encountered in practice.
For infrastructure provisioning, the end goal is to be able to create, maintain, change, and destroy parts or whole infrastructure (on-premise, cloud, or hybrid infrastructure) with minimal manual intervention. This playbook can include things like configuring and running infrastructure as code tools to set up different accounts and environments based on the needs (parameters), checklists for validating infrastructure, configuring DNS routes, VPNs, and proxies or diagnostic procedures for common occurring issues. Anything that is likely to be done multiple times (like the setup of VMs and LAMP stacks) and contains multiple steps should be at least documented using a playbook if not fully automated.
CI/CD pipelines are a well-known part of DevOps culture. Deploying the software to production can be nerve-racking like database migration until the process is done a bunch of times and/or is mostly automated. Some big companies have fully automated processes, but that’s not something that happens overnight. Hopefully, this will happen soon and without major incidents along the way. But this doesn’t mean that things can't go wrong or that if the system is fully automated, no playbook is required. Automated systems also need to be updated from time to time to suit business needs, so it’s a good idea to have a process written down.
Playbooks are very useful when it comes to deployment strategies and rollbacks. Take a look at this example of a big crisis in production for a major company: Facebook was down for 6 hours after a routine BGP update went wrong. Rollback and failover protocols, mitigation and problem migration protocols are something to include in the company’s playbook toolbox. It can come in handy, not because it is a routine operation, but because it needs to be executed smoothly and quickly when it happens.
The SRE team first needs to detect the issue to assess and escalate it. The same goes for software developers, DevOps, security engineers, product owners, and others that are part of the company's project(s). Early detection and prevention are based on monitoring, testing, and audits of the system and its compliance and performance. Some standard procedures revolving around this can be written in playbooks. An example of this could be the playbook for validating a new software tool that will be used on employees' computers, which must comply with the organization's standardized security protocols. Another example could be to have a guide or a checklist for doing internal pre-production or annual audits of the system.
It’s important to understand that if problems in production can happen to the giants such as Facebook, it can happen to anyone – it’s just a matter of time and the preparation level to mitigate failure and restore functionality quickly and effectively. A playbook for incident response can include more than just software and hardware steps. Chain of command and on-call information, internal and external communication (status page, incident press release), escalation protocols, and post-mortem analysis are just some of the response protocols in case of a production disaster.
Another example of a big company that has failed to do what they preach is Atlassian. Although their guidelines list communication as one of the top priorities in case of an incident, the April 4th incident demonstrated a lack of communication with the customers (even affected customers), until Day 9, when the company executives acknowledged the problem.
Keep in mind that the idea behind playbook can be utilized for more than just engineers' jobs - think about the whole scope of business and where a well-written, well-documented guideline can improve some process that makes business function.
Commonly used playbooks in Vega IT include production deployment and production readiness checklists, smoke test playbooks, as well as infrastructure (environment) setup and disaster recovery/rollback procedures. Do you have something similar that you or your company use?
Automation of playbooks and runbooks
Depending on the level of complexity and the desire to automate, playbooks, and especially runbooks, can be automated. To do that, we can use already existing (and probably familiar) tools like Ansible, GitOps, and Slack Integration Apps for this. If premium/freemium apps aren't suitable for your use case, check for existing open-source tools, or think about creating your own custom solution (scripts are always an option).

One great example where automation of runbooks is applicable is in infrastructure testing. Let's say that the infrastructure will be provisioned by some Infrastructure as a Code tool like Terraform. After deployment, the infrastructure needs to be tested and verified that it is working as expected and nothing has erred during the deployment. This is usually achieved using IaC tests (like Terraform test), API testing or automation testing (with tools like Selenium). When you know what needs to be tested, then it’s a lot easier to find a proper tool(s) for testing that will automate this part of infrastructure provisioning. To help you figure out what needs to be tested, you can start with a Runbook that describes all the steps (tests) that need to be executed to confirm a successful deployment.
Playbook automation is a lot trickier as the playbooks themselves can be more complex than the Runbooks. They can also include some manual approval steps that sometimes cannot be automated. And that is ok, if you automate the steps that can be automated and give enough information to people that are responsible for those manual steps. Example of this is when the CI/CD pipeline sends a Slack notification after the tests have passed to notify a team of a pending manual approval.
Not everything can or should be automated. Some high-risk and/or highly complex decisions could (and should) require human input, so automation cannot replace human intervention. Another example would be some Quality Assurance (QA) or User Experience (UX) testing, where a person will look and see if the product “feels” right. Sometimes adding automation for a low-risk process that happens rarely is not a good Return of Investment (ROI).

Taking all things into consideration, we can conclude that having playbooks and runbooks for your software system can greatly improve the quality of service of your software. It can help you have more confidence in your system and reduce the chance that an error occurs when you least expect it.
Where can you learn more about this topic?
Google, as the pioneer of the SRE, has a lot of good topics and a book on its website https://sre.google/, and we highly recommend starting the search for answers here.
Additional reading materials:
- https://www.iacdautomate.org/playbook-and-workflow-example
- https://microsoft.github.io/code-with-engineering-playbook/
- https://www.pagerduty.com/resources/learn/what-is-a-runbook
I hope you enjoyed reading this blog post and learned something new from it. Thanks for reading! :)
